






本文来自微信公众号:首义科创母基金黑丝黑木耳,作家:金能黑丝黑木耳,剪辑:Shanyunliu,题图来自:AI生成
想象一下,辞寰宇厨艺锦标赛上,你和一批有祈望的年青东说念主在一个破旧的毛坯灶台上,炒出来了惊艳全球的爆款转换菜。而你的敌手,在五星级旅社里指导数十东说念主的豪华团队,用着全球最贵的厨具和最多的食材,却在比赛中惜败于你,激发全球震憾。这不是爽文短剧,这是正在发生的热门。而你,等于低调麇集许久的“一代食神”——DeepSeek。
年头 DeepSeek App 横空出世,其转换性的架构瞎想和工程化落地使得模子性能在极低的成本下也能达到全球顶尖水平,加上用户体验精采的想维链展示和模子开源的容貌,在春节期间用户量飞快增长。
在激发全球慈祥的同期,全球本钱对中国科技金钱的从头评估与 AI 投资的底层逻辑也悄然发生摇荡。尤其是在大模子边界,夙昔巨额参加却多次推迟的ChatGPT5和本就步入下半场的国内六小龙,将直面 DeepSeek这匹黑马的强盛冲击。中国AI企业在DeepSeek冲突了“算力禁运”之后,正靠近高质地数据稀缺的挑战,尤其是高质地、低成本、多种类、多模态的数据,将成为明天 AI 产业发展的中枢要害。
一、DeepSeek 之前:被算力算法“智子”围困的中国 AI
主流的AI大模子试验容貌主如若基于 Transformer 进行下一个 Token 的展望。即从互联网为主要渠说念来汲取数千亿级的海量数据,并用进行雷同均值的匹配,对匹配收场偏差比较大的,也等于普通说的“大模子幻觉”(详见上篇《AI 幻觉的一体两面》),进行东说念主工打分/径直指引打标签,以此来普及模子的准确性。
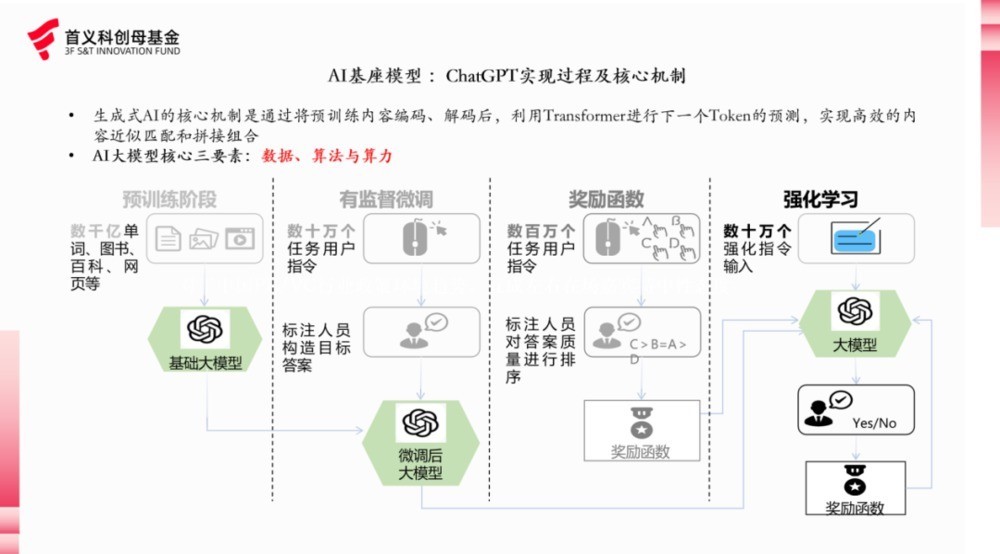
人所共知,AI 大模子中枢三要素即数据、算法和算力。数据对应的是“食材”,算力对应的是“厨具”,算规矩是“厨艺”。从全球范围来看,刻下算力的硬件性能已接近瓶颈,其迭代速率远不足大模子的日益增长的试验需乞降能耗压力。
而可供预试验的实践数据也迟缓见顶,2024 年 11 月份 OpenAI 前首席科学家 Ilya 在公开方位示意痛快地加多数据和瞎想身手来扩大刻下模子范畴的时期也曾收场。跟着大言语模子迟缓往多模态模子上发展,算力和数据的挑战则会进一步加重。
现在,算力方面我国靠近好意思国的“芯片禁令”的阻滞,使得国内 AI 公司没法使用高端好用的厨具,就像别东说念主用高压锅炖鸡汤一刻钟,咱们只可用柴火灶一直加柴熬两小时。在此配景下,我国发展东说念主工智能只可从算法和数据两个方面作念得更好,才有契机解围。
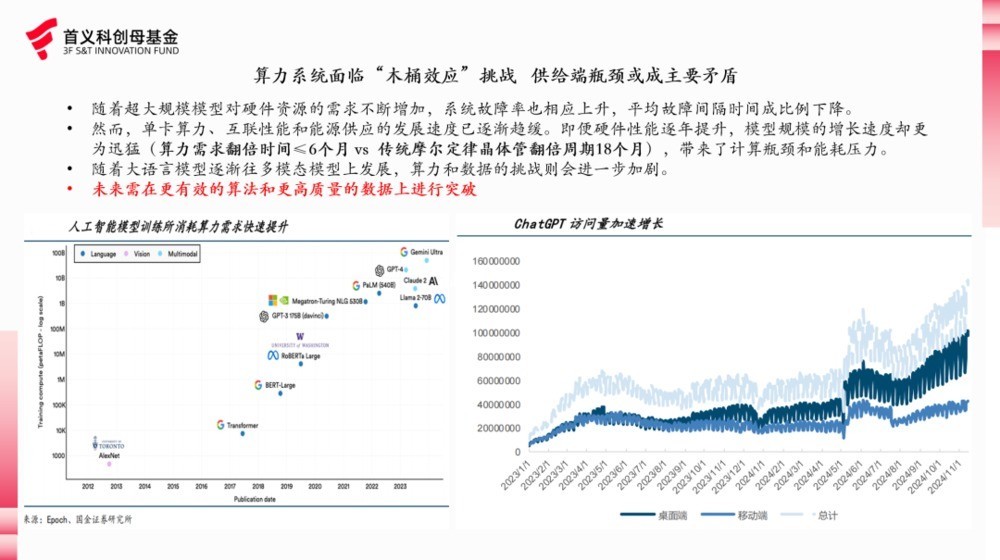
在算法方面,夙昔广阔不雅点是由于参加方面差别等,以致我国和OpenAI为代表的好意思国头部AI大模子公司有着至少1~2年的差距。左证CB Insights 发布的数据,2024年中国AI初创企业筹集的资金仅占好意思国AI初创企业的 7%。丰厚的资金储备意味能高薪招“全球终点奢睿东说念主”变成在研发转换上的碾压,进一步闲暇算法上风。在DeepSeekV3之前,我国东说念主工智能边界所靠近的情况不可谓不严峻。
二、高质地的可用数据,是企业应用AI最高出的挑战
在 DeepSeekV3和R1推出之后,顶尖的模子恶果和用户体验,加上其开源的特色,大大缓解了我国在算法和算力上的逆境,但数据方面的挑战依然存在。
数据是食材,食材的品性、丰富度及崭新度王人决定了最终菜品的口感和品性上限。关于大模子而言,高质地数据能够保险模子推理回答的准确性。而多模态多种类的数据,能普及模子的泛化性和推理身手,尤其是在机器东说念主的大脑(VLA 等)上。此外,还需要进行联网搜索并如期更新数据集,来确保模子复兴收场的时效性和准确性。
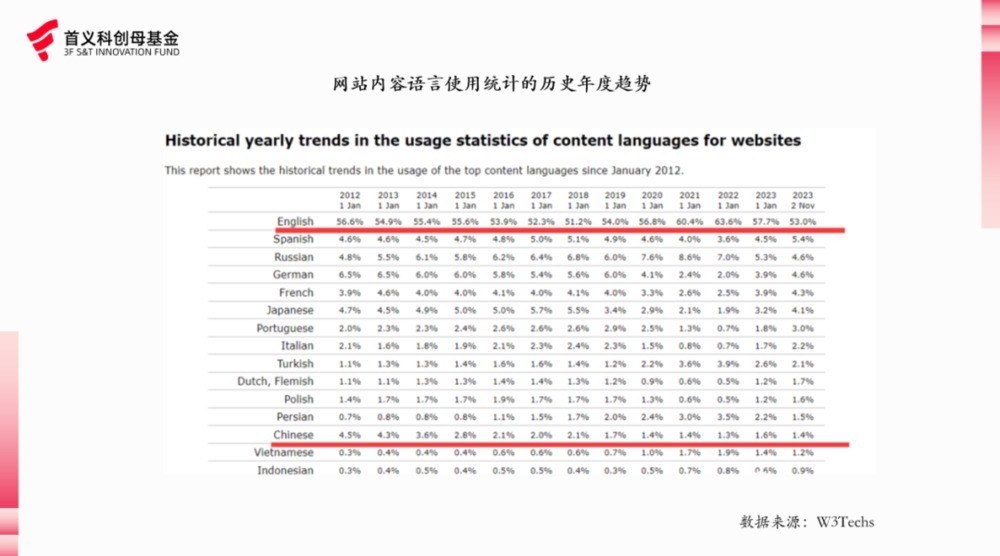
就可用数据量上,国内和海外有着自然差距。据W3Techs调研前一百万互联网网站使用的言语笔墨百分比,其中英文占比为59.3%,而汉文唯独 1.3%。比拟于好意思国的头部AI公司,国内可供试验的公开汉文数据不够多,模范化进程也不够高。
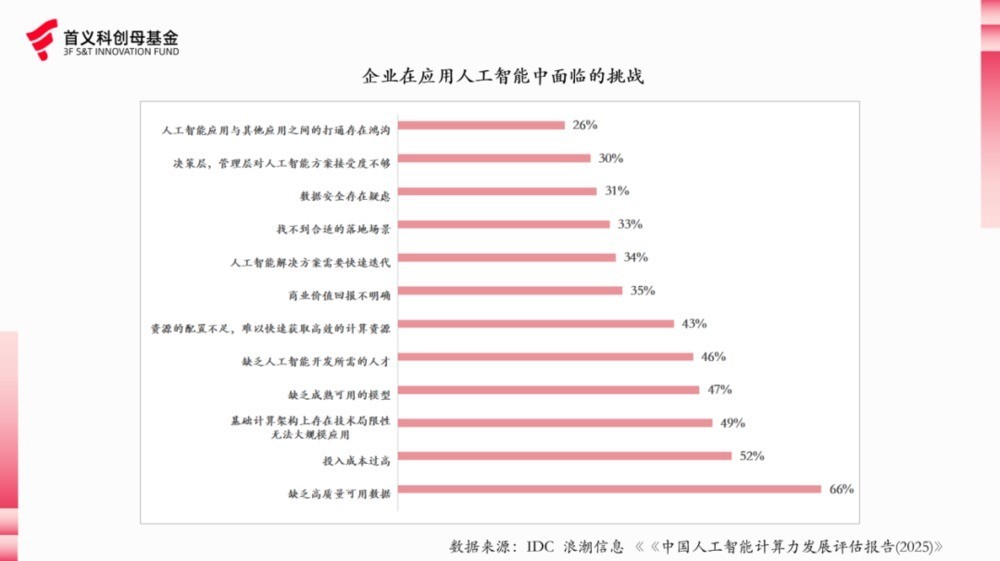
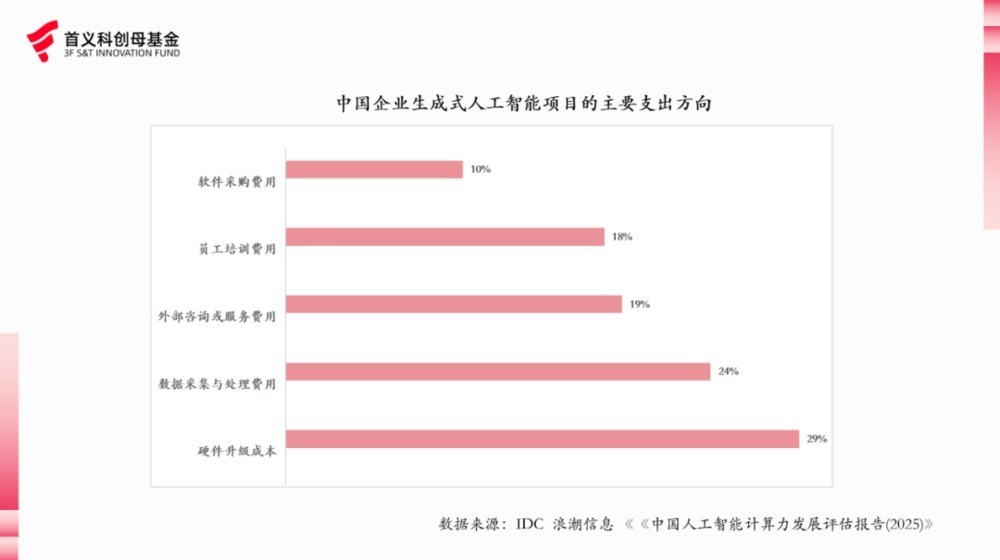
从收场来看,数据已是现在企业应用 AI 最高出的挑战。左证IDC和波浪信息发布的考虑走漏,现在企业在应用东说念主工智能中所靠近挑战最大的是缺少高质地可用数据,占比高达66%。在此之后才是成本高、技巧锻练度、东说念主才缺少等新兴边界通用挑战。
另一方面,数据相聚与处理是现在国内企业在生成式 AI 应用时的主要支拨标的,尤其是关于责任经由繁琐、决策链路较长、业务类型繁多的公司而言,其业务数据需要经过层层筛选、处理和业务谐和后,才能成为模范化的高质地数据,再用于模子的试验和推理。
三、像 DeepSeek 那样试验数据,要若何作念?
大致你毋庸像DeepSeek那样去试验数据,但了解他的试验规矩依然很有参考价值。
在DeepSeek之前,阿里的通义千问系列是全球主流的开源言语模子。旧年圣诞后DeepSeekV3发布本日,另类图片激情成人咱们对已有的信息作梳理分析:DeepSeek则弃取了转换性的架构(MLA+MoE),并惩办了好多微小的工程化落地艰巨,使得其在使用极低成本的情况下,成为那时最强的开源基础模子。
关于DeepSeek的要害,百度百科上的收场则是更为约略径直,即使用数据蒸馏技巧,得到更为细致、有用的数据。
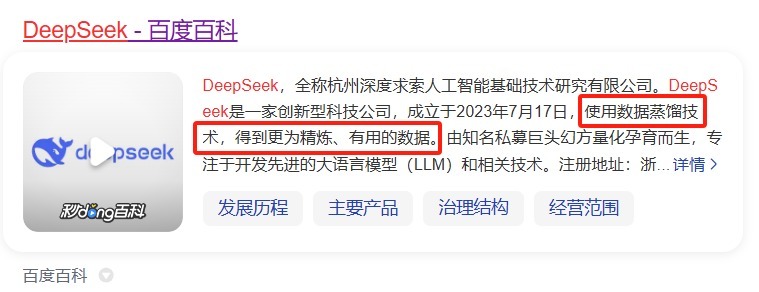 图片开端:百度百科
图片开端:百度百科
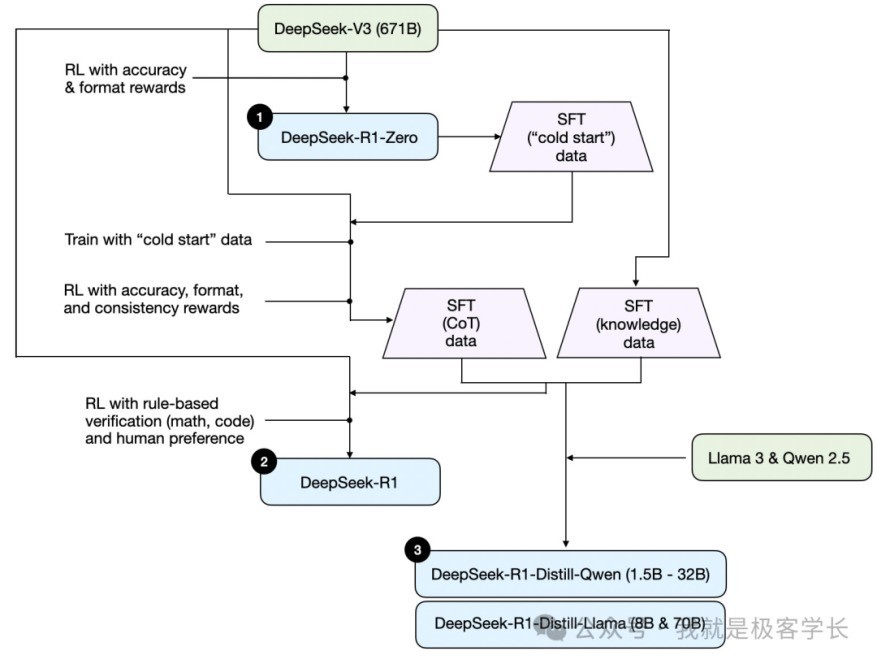
为了更深切谐和具体中枢思制,征引“极客学长”的论断:“回归来说,DeepSeek-R1-Zero 模子(以下简称“R1-ZERO”)的试验容貌就像教小孩学步辇儿,不径直告诉它正确谜底,而是让它我方尝试,左证收场的猛烈(比如谜底是否正确)来疏通我方的步履。这种方法不需要事先标注好的数据,透顶靠 AI 我方摸索,莫得输入任何带象征的数据,这亦然为什么这个版块的名字带 Zero 的原因,示意零样本输入。”
图片开端:公众号“我等于极客学长”
R1-Zero模子发扬至极惊艳,在数学和编程方面的身手也曾达到OpenAI-o1-0912的水平。但也存在显豁的弱势——生成的谜底可读性差,普通出现中英文混合。针对这个问题,DeepSeek团队弃取了一系列的优化轨范。
最初,用数千条东说念主工处理的高质地COT数据(比如精明的解题智力),通过监督微调(SFT)的容貌让它“冷启动”,再用强化学习进一步试验,使得生成的谜底更明晰,言语也更并吞。简而言之,即考虑东说念主员给了R1-Zero 模子一些优质例题,教它范例的解题体式,再用强化学习试验,使其解题又快又准,体式深邃。此时得到一个Checkpoint,并将该Checkpoint 称之为DeepSeek-R1-One(以下简称“R1-One”)。
然后,再用试验R1-Zero的容貌,用R1-One 生成一批高质地的COT数据(长想维链数据),同期再联接专科边界数据和东说念主为反映数据等,再以 DeepSeek-V3为基础模子进行强化学习,得到最终的DeepSeek-R1。
不错发现,DeepSeek除了在算法层面进行了一系列的转换和优化,其中枢智力中的数据王人是自行东说念主工处理或撰写的。如同投资东说念主朱啸虎在摇荡对大模子格调时所说,DeepSeek此次独一莫得公开的等于模子预试验数据。
图片开端:BOSS直聘
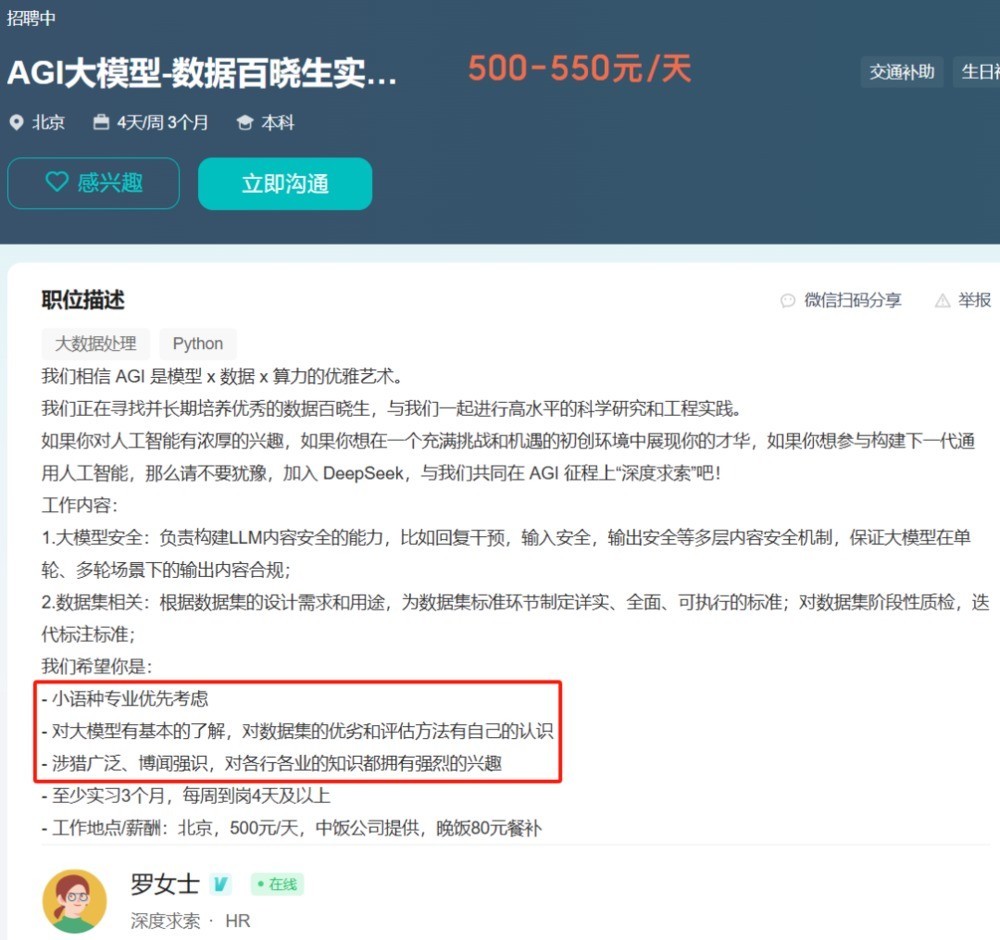
此外值得堤防的是,在爆火后DeepSeek开启了数据百晓生的实习生招聘,岗亭要求不高但薪资丰厚,也曾远超一般的数据外包公司全职东说念主员水平,从侧面体现出其对高质地数据的深爱进程。值得堤防的是,该岗亭优先探讨小语种专科,这大致是为了更好地进犯全球市时势作念的铺垫和准备。
四、具身智能、自动驾驶边界,不异靠近数据挑战
在近期的演讲及访谈中,上海交大博导、穹彻智能聚会创举东说念主卢策吾耕种指出:当下,具身智能的考虑阶梯正处于瓶颈期,具身智能靠近的两大中枢挑战之一是数据范畴存在“太平洋缺口”。工业级应用对具身智能设定了严格的红线模范,为达到这一模范,所需的数据量号称海量。但是,数据相聚形态难以灵验填补这一广阔的数据缺口。
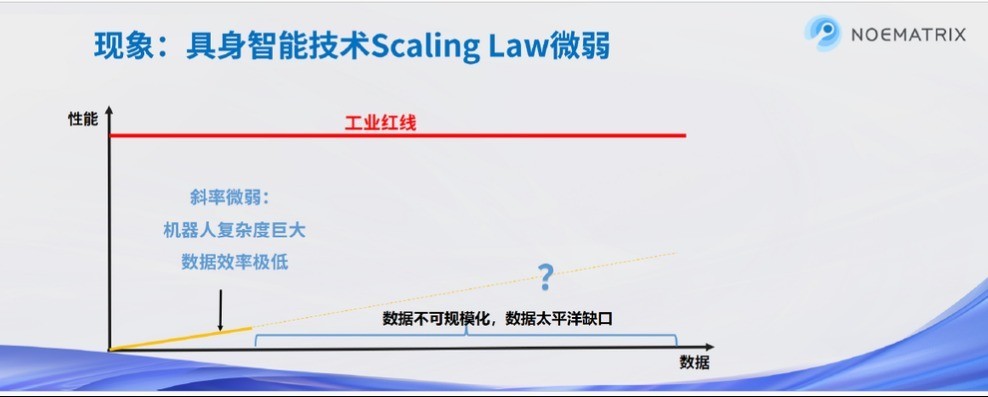
图片开端:NOEMATRIX
刻下数据相聚靠近着一系列难办问题:遥控操作需要购置价钱崇高的机器东说念主开采及权衡配套技巧,况且操作主说念主员需要经过专科培训。这些身分导致成本发愤,从而限制了数据相聚的范畴。
为冲突具身智能大模子的 Scaling Law 遏抑,完结数据相聚的范畴化并裁汰数据获取成本,需要找到一种既能保证数据果然性,又不影响东说念主们日常责任的数据相聚方法。
在自动驾驶边界,跟着 2024 年头始智驾边界走向端到端时期,数据的紧迫性空前普及。
端到端技巧的中枢在于通过巨额数据试验模子,使其能够识别和展望各样驾驶场景。高质地数据的输入,径直决定了模子输出的准确性和可靠性。这些数据不仅需要涵盖各样说念路条目、天气变化和交通情况,还要确保其标注的准确性和各样性。
传统模块化算法需要改变限制策略时,不错找到代码中具体的几行参数修改,之后测试 1%的案例即可,而端到端的算法中,小的蜕变需要从头对自动驾驶算法进行试验,难度了然于目。
因此,海量的、各样化的、优质的数据不可或缺,同期自动化、高水平的数据处理体系亦至关紧迫。左证业内众人见地,华为在智驾方面的一半参加用在了数据相聚和处理上。绝不夸张地说,端到端时期,数据会占据自动驾驶开发中 80%以上的研发成本。
从数据维度看,海量且优质的数据正成为自动驾驶行业的“稀缺品”。自动驾驶弃取的BEV感知决策,需要达到1亿帧以上的试验数据才能甘心车规要求,不然泛化性、准确率和调回率就难以保险。
以特斯拉为例,马斯克曾示意,特斯拉FSD测试里程需要达到60亿英里,才能甘心全球监管机构的要求,这亦然自动驾驶系统完结质变的一个紧迫节点。2024年5月,在惩办了算力瓶颈之后,马斯克示意更大的难点在于对长余数据的相聚,其获取难度和成本对比通用数据则是指数级激增。业内现在广阔不雅点是,长余数据只可通过仿真或数据生成的容貌来惩办。
五、获取高质地数据的“三板斧”:标注、相聚、生成
标注、相聚和生成,是现在获取高质地数据的三种容貌。
数据标注,主要分为东说念主工标注和机器东说念主标注。发展于今,内容应用中以东说念主机协同标注为主,即企业开发的自动化标注平台,先对入库数据进行预标注,简约东说念主力的同期保证一定的准确度。再由专科或有警戒的东说念主员对机器预标注的数据进行进一步的辩别和处理,进一步普及数据质地和准确度。跟着技巧和业务的发展,明天有望出现自动化标注进程和准确性均较高的平台或软件,在大模子产业链中东说念主力参与最紧迫的要道降本增效。

数据相聚,现在数据相聚主要通过东说念主工、开采或者爬虫等容貌进行相聚。数据相聚普通面向除语料、图片和视频外更各样的数据,所应用边界也愈加鄙俚,除了东说念主形机器东说念主边界所鄙俚应用的动捕相聚照旧自动驾驶边界鄙俚应用的实车相聚,还包括 AI4S 和机器视觉边界主要应用的开采参数相聚和实景三维相聚等。
现在数据相聚是上述前沿科技边界的必备要害要道,其成本亦然高居不下。因此,上述行业内也催生出高质地高效用进行数据相聚、加工处理和挖掘分析的痛点诉求。随之助长而生的等于数据生成。
数据生成主如若通过数据彭胀、展望或限制条目下的立地生成等容貌进行,现在处于发展早期,其中获取鄙俚慈祥的是寰宇模子。寰宇模子的宗旨是生成可剪辑、有物理特色的高质地捏造场景,完成对实践寰宇的复刻或捏造寰宇的构建,从而在内部进行数据的处理和模子的试验,在数据获取成本和各样性上具有发展远景。
但值得堤防的是,寰宇模子是通过算法来完结的,在数据精度上难以匹敌的高精密仪器开采的实景或什物相聚,并不成透顶替代数据相聚,但不错完结至极灵验的互补。
六、筑牢“高质地数据地基”,政府正加速行径
本年以来,为惩办东说念主工智能产业中的数据痛点,多地政府加速推动高质地数据开发。
2月19日,国度数据局在北京召开高质地数据集开发责任启动会。这不仅彰显了国度对数据要素的高度深爱,也预示着我国数据产业发展将迈入新阶段。
2月18日,《武汉市促进东说念主工智能产业发展些许战略轨范》的发布会上明确将聚焦工业制造、医疗健康、科研转换等12个行业边界,鼓舞环球数据、企业数据与个东说念主数据分类分级开发愚弄,开发不少于20个高质地数据集。
3月18日,武汉市数据局发布援手高质地数据集开发和数据家具愚弄的公开征求见地稿,对权衡单个标的给以最高 200 万元的援手。
3月3日,深圳市工信局于发布《深圳市加速打造东说念主工智能前卫城市行径瞎想(2025—2026年)》,明确加速构建高价值垂类数据集和具身智能数据集。其中明确指出,将变成3PB汉文语料数据,并在宝安、龙华两个区开发具身智能数据相聚基地,变成多模态试验的开源数据集。
咱们能看到,连年来由大疆、DeepSeek、“六小龙”所展现的中国科技转换变革并非局部的突发事件,而是举国推动科创时期下,东说念主才红利重迭完备产业链变成坚实基础,并由科研型企业家完结范式转换,完成从量变到质变的收场呈现。
还有好多尚在量变麇集的优秀创业者和研发团队在昼夜兼程,政府也在积极推动基础设施开发给转换提供泥土,历史反复应验,曾种过的种子王人会着花收场,仅仅需要时期和机缘罢了。
参考贵府:
1、新浪财经,《外媒:DeepSeek受慈祥 登顶140国应用商店榜首》
2、上不雅新闻,《转换记录!DeepSeek成史上最快冲突3000万日活APP》
3、IDC、波浪信息,《2025年中国东说念主工智能瞎想力发展评估叙述》
4、极客学长,《DeepSeek R1 破圈的中枢技巧解读,你不成不知说念的 AI 干货!》
5、无相君,《中好意思大模子的差距,究竟在哪儿?》
6、张小珺,《朱啸虎实践主义故事1周年连载:“DeepSeek快让我坚信AGI了”》
7、穹彻智能,《2025 全球开发者前卫大会:具身智能语料工程启动,“坐蓐跟随” 引颈明天》
8、极智GeeTech,《无数据不智能,数据闭环重塑高阶智驾明天》
9、复旦大学 张奇耕种,《生成式AI大会(上海站)2024》公开演讲
10. 国金证券,《AI行业要害时刻:瓶颈与机遇并存》
本文来自微信公众号:首义科创母基金,作家:金能
Powered by cable av 国产 @2013-2022 RSS地图 HTML地图
Copyright Powered by站群系统 © 2013-2024